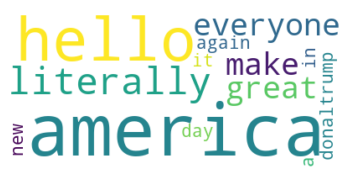Example usage
To use pytextprep in a project:
Imports
import re
from pytextprep.extract_ngram import extract_ngram
from pytextprep.extract_hashtags import extract_hashtags
from pytextprep.remove_punct import remove_punct
from pytextprep.generate_cloud import generate_cloud
import pytextprep
import matplotlib.pyplot as plt
Create list of Tweets
tweets_list = [
"hello literally everyone",
"hello #America!",
"Make America Great Again! @DonalTrump",
"It's a new day in #America"]
Remove punctuation
cleaned_tweets = remove_punct(tweets_list, skip=["'", "@", "#", '-'])
cleaned_tweets
['hello literally everyone',
'hello #America',
'Make America Great Again @DonalTrump',
"It's a new day in #America"]
Extract ngrams
extract_ngram(cleaned_tweets, n=3)
['hello literally everyone',
'literally everyone hello',
'everyone hello #America',
'hello #America Make',
'#America Make America',
'Make America Great',
'America Great Again',
'Great Again @DonalTrump',
"Again @DonalTrump It's",
"@DonalTrump It's a",
"It's a new",
'a new day',
'new day in',
'day in #America']
Generate word cloud
fig, wc = generate_cloud(tweets_list)
plt.show()
[nltk_data] Downloading package stopwords to /home/docs/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.